| Хранилища данных, OLAP, CRM: информация |
Агрегированные таблицы в Oracle BI SuiteАвтор: Егор Демьянов (все статьи)
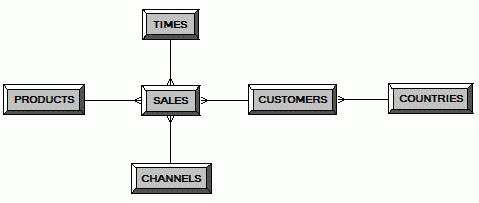
В ROLAP-хранилищах данные хранятся на значительно более детальном уровне, чем в большинстве случаев требуется для анализа. Например, продажи могут храниться по чекам, в то время как для анализа может в основном требоваться объём продаж за неделю или месяц. В этом случае на помощь может прийти использование агрегированных таблиц. Рассмотрим использование агрегированных таблиц в Oracle BI Suite EE. В качестве примера взята схема SH из Oracle Database, в которой хранятся продажи некоторого гипотетического магазина. На базе этой схемы я настроил репозиторий, с использованием которого можно повторить описанный далее пример. Физическая модель имеет форму снежинки:
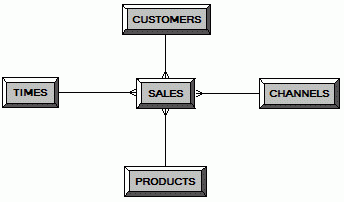
Логическая модель еще проще:
В таблице фактов SALES содержится 918843 записи. Для измерений созданы иерархии со следующими уровнями (от самого высокого к самому детальному, в скобках обозначено количество элементов на каждом уровне):
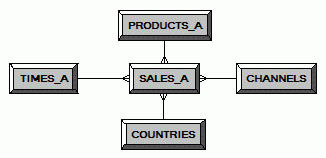
Предположим, что аналитикам часто требуется отчет с месячными объемами продаж товаров в разрезе по странам и категориям товаров. Построение такого отчета на основе детальных данных может потребовать использования значительных ресурсов, поэтому было принято решение создать таблицу, в которой объемы продаж уже сагрегированы до нужных уровней иерархии. Итак, нам потребуются агрегированные таблицы для измерений. В таблице TIMES лежат записи о днях, создадим таблицу с записями о месяцах:
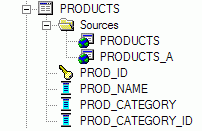
Переходим к настройке логической модели. Перетаскиваем физическую таблицу PRODUCTS_A на папку Sources для логической таблицы PRODUCTS.
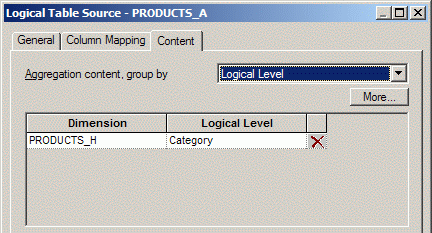
Затем открываем свойства источника PRODUCTS_A и на вкладке Content указываем, что данные из этого источника соответствуют уровню иерархии Category:
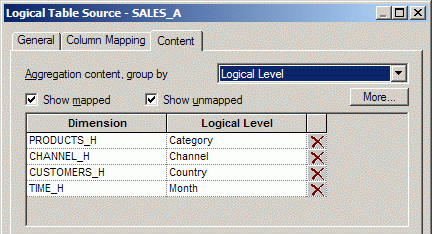
Проделываем то же самое с физической таблицей TIMES_A и логической таблицей TIMES, указав уровень Month. Затем, выполняем аналогичную операцию с физической таблицей SALES_A и логической таблицей SALES, также указав соответствующие уровни иерархий:
Если все сделано правильно, и Consistency Check Manager не выдает ошибок и предупреждений, то посмотрим, как используются наши агрегаты. Заходим в Oracle Answers под пользователем, для которого включено логирование на уровне=2 и выполняем следующий запрос:
Теперь открываем NQQuery.log, и видим, что созданному Answer соответствует такой sql-запрос:
В этом примере мы создали один агрегат, но подобным образом можно сделать несколько агрегатов, для разных комбинаций уровней иерархий. При наличии нескольких агрегатов может возникнуть ситуация, когда Oracle BI Server для обработки запроса сможет использовать любой из нескольких подходящих агрегатов, и должен будет выбрать какой-то один. Предположим, что в нашем примере мы создали еще один агрегат SALES_A2 для уровней TIMES(Year), CUSTOMERS(City), CHANNELS(Total), PRODUCT(Category). Для получения объема продаж по годам и регионам BI Server может использовать как SALES_A, так и SALES_A2. Стоимость использования того или иного источника оценивается с использованием количества элементов на уровнях иерархий.
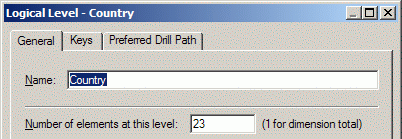
Потенциальное количество строк для получения требуемого результата из SALES_A оценивается как (60 месяцев * 23 страны * 5 каналов * 5 категорий) = 34500. Для SALES_A2 потенциальное количество строк оценивается (5 лет * 620 городов * 5 категорий)=15500. Таким образом BI Server решает, что выгоднее использовать SALES_A2.В принципе, не произойдет ничего фатального, если не указывать количество элементов для уровней иерархий. Вопрос только в том, насколько эффективно будут использоваться агрегаты. Для автоматической оценки количества элементов можно использовать команду Estimate Levels в контекстном меню для измерений.
По этой теме также можно почитать:
Для удобства отслеживания новых публикаций на сайте рекомендую подписаться на рассылку или подписаться на канал RSS.
Если вы нашли в сети интересные ссылки на ресурсы по технологиям хранилищ данных, OLAP, CRM или data mining, и хотите поделиться ими с другими, присылайте их. Я с удовольствием размещу их на этом сайте. |
[AD] |

[ На главную | Книги | Ссылки | Рассылка | Письмо автору | Реклама на сайте ]
© Константин Лисянский, 2001-2008.