| Хранилища данных, OLAP, CRM: информация |
Подсистема сопоставления записей в хранилище данных (часть 2)Автор: Дмитрий Орлов Как работает подсистемаПри инициализации подсистемы необходимы произвести некоторые начальные действия, которые включают в себя процесс формирования и обработки эталонных наборов, а так же преобразование данных рабочих наборов. Эти операции будем считать вспомогательными и в контексте собственно процесса сопоставления рассматривать не будем2. Подсистема работает по принципу трехступенчатого фильтра, т.е. имеет в своем составе три ступени «фильтрации»3 данных:
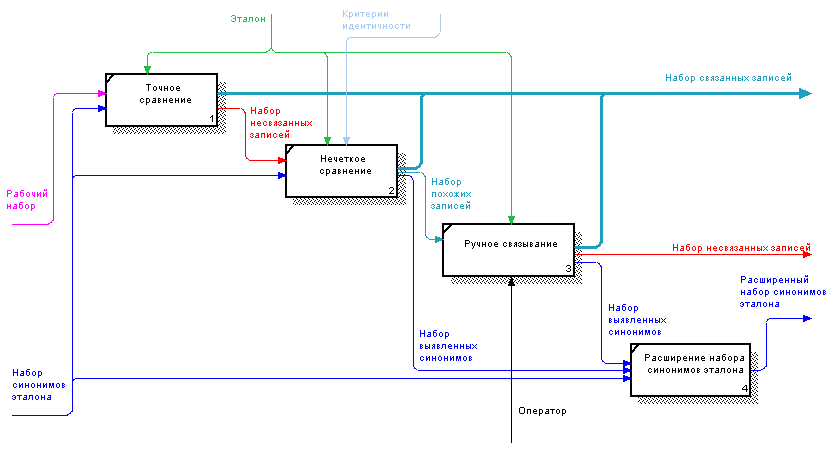
По завершении рабочих стадий необходимо произвести расширение набора синонимов эталона за счет вновь выявленных, на втором и третьем этапе, связей «эталон-рабочий образец» (согласно п.7). Расширение словаря синонимов возможно реализовать, как дополнительную функцию GUI программы, используемой оператором на стадии ручного связывания, либо как хранимую процедуру (stored procedure). Хочется подчеркнуть, что расширение словаря синонимов играет ключевую роль в подсистеме, т.к. во время следующего сеанса загрузки данных в ХД, нагрузка на оператора значительно уменьшится, либо дело вообще не дойдет до стадии ручного связывания, т.к., возможно, все необходимые связи будут обнаружены уже на стадии точного сравнения! Теперь, когда имеется представление об основных принципах работы подсистемы, можно ознакомиться с процессом сопоставления более наглядно с помощью предоставленной ниже диаграммы. IDEF0 диаграмма процессаНа диаграмме процесса средствами IDEF0, по сути, изложено то, о чем уже говорилось выше. Но все же, не помешают некоторые дополнительные пояснения. Рис.1 IDEF0 диаграмма процесса сопоставления записей (щёлкните для просмотра)
Во-первых, интерпретация набора синонимов, как ресурса, подлежащего преобразованию [4] вполне обоснована, учитывая наличие (и важность!) стадии расширения набора синонимов, несмотря на то, что логически он является частью эталона. Во-вторых, обязательно должен последовать вопрос, что это за набор несвязанных записей на выходе? Вопрос закономерный, и существует, как минимум, три ответа на него:
Автор при испытании прототипа подсистемы получил на выходе такой набор, и хотя записей было достаточно мало, что делало его пригодным для ручного связывания (около десятка записей), попробовал пропустить его еще раз через стадию нечеткого сравнения с менее строгими условиями. Это дало определенный эффект – несколько записей «нашли» свои эталоны, но были и неверные соответствия. Так что, в принципе, возможно применение повторного цикла нечеткого сравнения с более мягкими критериями, при наличии на выходе несвязанных записей. Также, стоит заметить, что наличие потока «Набор связанных записей» на стадии нечеткого сравнения носит, скорее, символический характер, т.к. на практике вряд ли представляется возможным реализовать полностью однозначный критерий, применимый на этой стадии. Критерий качестваКак говорилось выше, подсистема должна минимизировать участие человека
в процессе сопоставления. Исходя из этого и определим критерий качества
подсистемы4 - минимальное
число итераций с участием оператора, позволяющее достичь полного
сопоставления рабочего набора с эталоном. Другими словами – это
скорость расширения набора синонимов до уровня, включающего все
элементы рабочего набора.
2) Однако, необходимо упомянуть, что преобразование данных при инициализации (как эталонных, так и рабочих), включает в себя процесс нормализации строк, т.е. удаления незначимых символов и подмены всех возможных комбинаций разделителей одним пустым символом алфавита, что вполне допустимо, исходя из п.4, и позволяет повысить инвариантность представления атрибутов. 3) Сравнение с фильтром и термин «фильтрация» использован не случайно, т.к. на каждой стадии происходит отсеивание данных (согласно п.8), что уменьшает нагрузку на каждую последующую стадию. Заметьте - только в последней стадии подразумевается участие оператора-человека, что полностью согласуется с одной из целей создания подсистемы. 4) Величина критерия качества во многом
зависит от предметной области, характера данных, полноты эталонных
наборов и качества критериев идентичности, используемых при нечетком
сравнении, что делает его достаточно объективным.
Продолжение следует...
Для удобства отслеживания новых публикаций на сайте рекомендую подписаться на рассылку или подписаться на канал RSS.
Если вы нашли в сети интересные ссылки на ресурсы по технологиям хранилищ данных, OLAP, CRM или data mining, и хотите поделиться ими с другими, присылайте их. Я с удовольствием размещу их на этом сайте. |
|
{kind=link}
[ На главную | Книги | Ссылки | Рассылка | Письмо автору | Реклама на сайте ]
© Константин Лисянский, 2001-2008.
![]()