| Хранилища данных, OLAP, CRM: информация |
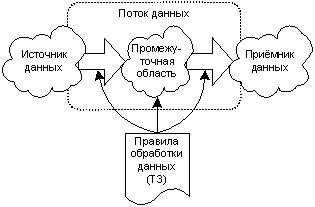
Порядок разработки ETL-процессовАвтор: Евгений Островский АннотацияИзвлечение, преобразование и загрузка, известные среди специалистов по базам данных под аббревиатурой ETL (Extract, Transform and Load), — это основные этапы переноса информации из одной базы данных (приложения) в другую. Для достижения успеха при проектировании переноса данных из одной системы в другую крайне важно четко представлять процессы обработки данных, а также структуру данных исходного приложения и приложения назначения. Данная статья описывает общие правила разработки ETL-процессов и определяет последовательность операций при загрузке хранилища данных (ХД) из источников данных. ВведениеСтандартизация последовательности операций при загрузке ХД, учитывая важность и стоимость многих решений ETL, позволит избежать повторения ошибок, сделанных в предыдущих разработках. Кроме того, опыт разработки ETL выявил общие части ETL-процессов при загрузке разнородных источников, что позволяет говорить о единообразии подхода к разработке ETL для источников данных произвольного происхождения. Проще говоря, приложения ETL извлекают информацию из исходной базы данных, преобразуют ее в формат, поддерживаемый базой данных назначения, а затем загружают в нее преобразованную информацию. Для того чтобы инициировать процесс ETL, применяются программы извлечения данных для чтения записей в исходной базе данных и для подготовки информации, хранящейся в этих записях, к процессу преобразования. Чтобы извлечь данные из исходной базы данных, можно выбрать один из трех вариантов: создать собственные программы, обратиться к готовому специализированному инструментарию ETL или использовать сочетание и того и другого. В производственном центре Datagy создан собственный оригинальный инструментарий, который позволяет сочетать технологические приемы, сложившиеся в Datagy, с программами независимых разработчиков, которые выполняют специализированные функции, уникальные для конкретного окружения. Во многих случаях существующий инструментарий ETL способен удовлетворить большую часть требований к переносу данных. Описав в целом задачи и преимущества ETL-процессов, давайте рассмотрим их место и алгоритм работы в процессе построения хранилищ данных. Структура процесса перегрузки данныхПроцессВ общем случае, программист ETL может представлять себе архитектуру ХД в виде совокупности трёх областей: источник данных (совокупность таблиц оперативной системы и дополнительных справочников (классификаторов, таблиц согласования), позволяющую создать многомерную модель данных с требуемыми измерениями), промежуточная область (совокупность таблиц, использующихся исключительно как промежуточные при загрузке ХД) и приёмник данных. Движение данных от источника к приёмнику называют потоком данных. Необходимые потоки данных формирует и описывает аналитик.
Таблица 1: Основные стадии процесса загрузки данных Процесс перегрузки данных – это реализация потока данных от единственного набора данных источника до одного или нескольких наборов данных ХД. Различают следующие классы процессов: 1. По характеру загрузки:
2. По виду источника данных:
Процесс перегрузки данных включает в себя одну или несколько фаз, которые выполняются по очереди, в зависимости от типа фазы. ФазаФаза процесса перегрузки данных (подпроцесс, обеспечивающий решение определённой задачи в рамках ETL-процесса) соответствует стадии загрузки источника данных, то есть количество используемых фаз ограничено стадиями, которые должен пройти набор данных источника, чтобы быть загруженным в ХД. Фаза состоит из шагов и может включать операции управления выполнением перегрузки. Управление выполнением заключается в анализе количества записей в ключевых таблицах и флагов состояния, и реализуется с помощью языка скриптов утилиты SQLExecutor. ШагШаги представляют собой отдельные SQL-запросы, которые выполняют
единичные действия по перегрузке, преобразованию и выборке данных. Группа процессовГруппы процессов введены для организации периодических перегрузок данных и указывают чёткую последовательность выполнения процессов внутри группы. Стадии загрузки источника данныхВ процессе загрузки, данные проходят следующие основные стадии, каждая из которых реализуется в виде отдельной фазы процесса перегрузки данных:
1 Операция резервирования BACKUP в основной массе проектов по созданию двухуровневых ХД не применяется. Требуется дальнейшее рассмотрение целесообразности введения этой операции вообще, так как она может быть заменена применением SCD уровня 2 и выше. 2 Операция удаления записей из ХД в общем случае не реализуется из-за отсутствия потребности в ней. Решение о её создании принимается каждый раз, если того требует техническое задание.
Для удобства отслеживания новых публикаций на сайте рекомендую подписаться на рассылку или подписаться на канал RSS.
Если вы нашли в сети интересные ссылки на ресурсы по технологиям хранилищ данных, OLAP, CRM или data mining, и хотите поделиться ими с другими, присылайте их. Я с удовольствием размещу их на этом сайте. |
[AD] |
[ На главную | Книги | Ссылки | Рассылка | Письмо автору | Реклама на сайте ]
© Константин Лисянский, 2001-2008.