Материал опубликован с разрешения компании
Автор оригинала: Warren Thornthwaite (все
статьи)
Перевод на русский язык: Егор
Демьянов
Оригинальный документ располагается здесь.
Пользователи часто хотят видеть данные, сгруппированные различным
образом. В простейшем случае одно подразделение (к примеру, маркетинговый
департамент) имеет свою иерархию клиентов, а другое подразделение
(к примеру, отдел продаж) хочет видеть другую иерархию. Если все
действительно настолько просто, то имеет смысл включить обе иерархии
в измерение «Клиент» и назвать их правильным образом. К сожалению,
большее число иерархий, встроенных прямо в измерение, сделает его
малопригодным для использования.
Необходимость более гибкой реализации дополнительных иерархий возникает
тогда, когда несколько подразделений хотят видеть данные по-своему,
причем в нескольких разных вариациях. В таком случае необходимо
поработать с пользователями и определить наиболее распространенную
группировку данных. Эта группировка станет стандартной иерархией
используемой по умолчанию, и будет встроена прямо в основную таблицу
измерения. Также можно поступить еще с несколькими наиболее широко
используемыми иерархиями для простоты работы пользователей.
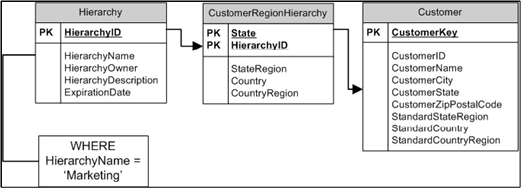
Для поддержки дополнительных иерархий создается отдельная таблица,
с помощью которой пользователь может сгруппировать данные по любой
из имеющихся иерархий. На рисунке показан пример такой промежуточной
таблицы (bridge table) CustomerRegionHierarchy для группировки по
географическому положению.
Каждая иерархия в промежуточной таблице должна быть полной, т.е.
начинаться с того уровня базового измерения, к которому присоединена
промежуточная таблица, и заканчиваться самым верхним уровнем. К
примеру, таблица CustomerRegionHierarchy соединена с уровнем State.
Конечно, можно начать и с более детального уровня, такого как ZipPostalCode,
но это приведет к увеличению таблицы и может не дать никаких преимуществ.
С другой стороны, если есть четкое требование по созданию альтернативных
группировок почтовых индексов, то таблица с дополнительными иерархиями
естественно должна начинаться с уровня ZipPostalCode.
Для упрощения анализа и создания отчетов промежуточная таблица
должна содержать описание и стандартной иерархии. Стандартная иерархия
становится используемой по умолчанию во всех предварительно настроенных
отчетах, но пользователю представляется возможность переключиться
на другую иерархию. Отдельная таблица Hierarchy с одной строкой
на каждую иерархию упрощает поддержку системы, но визуально усложняет
дизайн. При необходимости можно провести денормализацию и объединить
Hierarchy и CustomerRegionHierarchy.
Таблица CustomerRegionHierarchy должна использовать только в предварительно
настроенных отчетах, либо опытными пользователями. Если не ограничить
HierarchyName единственным значением, то в результате соединения
таблиц Customer и CustomerRegionHierarchy каждый клиент будет посчитан
несколько раз. Каждый отчет, в котором используются дополнительные
иерархии, должен использовать стандартную иерархию по умолчанию,
и позволять выбирать дополнительные иерархии строго по одной.
Дополнительные иерархии - хороший пример дополнительных преимуществ
хранилищ данных. Такие индивидуальные группировки данных широко
используются пользователями, но определения этих группировок не
централизованы и не формализованы. Обычно они хранятся где-нибудь
в электронных таблицах на компьютерах пользователей.
Если вы нашли в сети интересные ссылки на ресурсы по технологиям
хранилищ данных, OLAP, CRM или data mining, и хотите поделиться
ими с другими, присылайте их.
Я с удовольствием размещу их на этом сайте.